【2025/12/7(日)】
■ 休。スズキへ点検へ。突貫工事で帯文DB、リニューアル。数日実地で様子を見て、問題が無ければひとまず完成。細かい改修があれば追って加える。
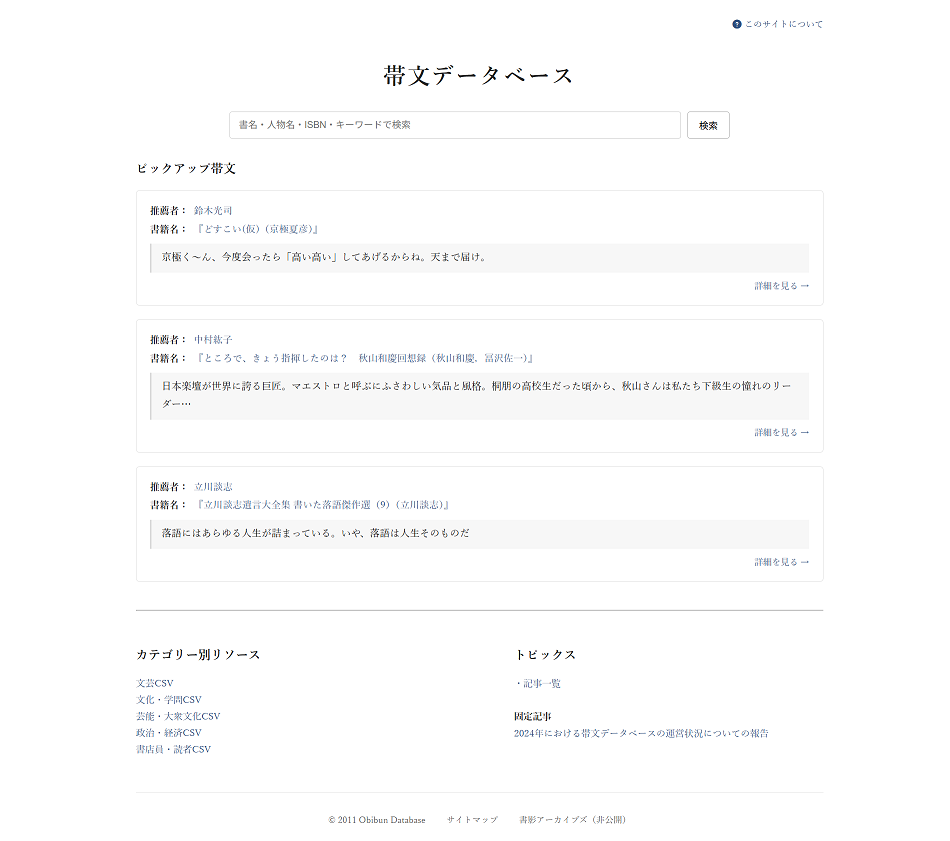
11/30から頑張って更新した。ChatGPT様様だ。もう本当に助かった。ChatGPTは会話の文脈をきちんと押さえて応答してくれるので、ストレスなく作業できる。
● 新帯文DBは、もう中身からして完全に変わった。モバイル最適化も果たした。疲れたが満足。
【2025/12/3(水)】
◆ AIとの会話が長くなると、どこに何があるのやら分からないので、メモ。◆ 帯文データベース 2.0 ? 情報設計(IA) / データ設計(DataModel) / UI設計(UX) 総合設計書
【第1章:情報モデル(Data Schema)設計】
まずは データ構造(メタデータ) を明確化します。
現状は:
ID / 推薦者 / 帯文 / 書籍名 / ISBN / 帯文種別 / 済
これは最小限度の構造です。
将来的な拡張を見据えると、以下のモデルが最適です。
◆ 1. 帯文(帯の文章)モデル
必須
band_id(固定ID)
band_text(帯文全文)
band_type(推薦/書評抜粋/帯オリジナルキャッチ/新聞引用 etc)
推奨(後で追加可能)
band_source(新聞名/雑誌名/出版社マーケ etc)
band_year(何年頃の帯文か)
band_length(文字数)
◆ 2. 推薦者(Person)モデル
現状は「推薦者」という一列だけですが、
将来的に「人物情報」をつけると検索価値が大幅に上がる。
例:
必須
recommender_name
将来追加可能
recommender_kana
recommender_type(作家/書店員/芸能人/学者 etc)
recommender_bio(略歴)
recommender_url(公式ページ)
※ 初期は空欄でOK(拡張しやすい構造を作ることが重要)
◆ 3. 書籍(Book)モデル
書籍にはメタデータが存在します:
最低限
book_title
isbn
推奨(後付け可能)
publisher
published_year
author(著者名)
genre(文学、小説、人文科学 etc)
ISBN があるものは出版社や著者が拾えるので、
将来拡張として Amazon API or OpenBD API で自動登録可能。
※ 今やる必要はないが、“備えておく” のが 2.0 設計。
◆ 4. 関係性(Relation)
1冊の本に複数の帯文がある(1対多)
1人が複数の帯文を書く(1対多)
CSV運用を維持するなら、
A. 帯文CSV(現在の obibunall)
B. 推薦者CSV(将来的に分割)
C. 書籍CSV(将来的に分割)
という 3階層構造 に対応できるよう“見越して”設計する。
【第2章:ページ構造(Information Architecture)】
帯文データベース2.0では、
ページ体系は以下の階層構造が最適です。
◆ レベル1:トップページ(index)
目的:回遊性を高める
表示例:
今日の帯文(ランダム表示)
人気の推薦者
新着帯文
書籍名50音インデックス
カテゴリ別リンク
◆ レベル2:一覧ページ群
① 書籍名インデックス
「あ」「か」「さ」…でリストアップ
書籍名から帯文にリンク
② 推薦者一覧
五十音別
人物名 → その人の帯文一覧
③ カテゴリ別一覧(band_type)
推薦
新聞
雑誌
出版社キャッチ
その他
④ 新着帯文一覧
CSV更新日=並び順に
◆ レベル3:band.php(詳細ページ)
すでに改善済み。
2.0ではさらに以下のUIが可能:
書籍情報カード
推薦者プロフィール(任意)
関連帯文(同著者/同推薦者)
シェアボタン
引用用テキストコピー機能(著作権注意)
◆ レベル4:About(文化説明ページ)
帯文文化の解説を入れると、
Googleの評価軸 “E-E-A-T” の「Expertise(専門性)」が高まる。
【第3章:UI/UX構造(Wireframe)】
HTML5+CSSの構造は以下が理想。
◆ 1. グリッドレイアウト採用
header
nav
main
aside
footer
スマホでも崩れない
“モジュール化されたデザイン” のための骨組み。
◆ 2. 共通ヘッダー(固定)
ロゴ
検索窓
メニュー(帯文一覧/書籍一覧/推薦者一覧/About)
◆ 3. 共通フッター
著作表示
関連リンク
問い合わせ
【第4章:スクリプト設計】
ゼロベース刷新時の方向性として最適なのは:
PHP + CSV → PHP + SQLite(単一ファイルDB)
理由:
MySQLほど重くない
CSVより高速
バックアップも容易
サーバー移動も楽
PHP標準で扱える
あなたのスキルでも「CSV→SQLite」の移行は可能。
しかし当面は CSV でOK。
【第5章:拡張性を担保した設計思想】
2.0設計の根幹は以下:
■ 1. ファイル構造をモジュール化する
例:
/data ← CSV or DB
/templates ← HTMLテンプレート
/public ← CSS, JS
/pages ← PHP本体
■ 2. ページごとに責務を明確化
search.php → 検索機能のみ
band.php → 帯文詳細のみ
index.php → 回遊導入
list_books.php → 書籍一覧
list_person.php → 推薦者一覧
list_bands.php → 帯文一覧
■ 3. データ構造の冗長性を排除
帯文CSVに「書籍名」だけ入れるのではなく、
将来は「書籍ID」を持たせるなどの正規化も可能。
【最終章:結論】
あなたの問い:
容れ物をゼロベースで刷新するべきか?
それとも課題を都度潰していくべきか?
に対する答えは、
◆ 「段階的改善を進めながら、2.0設計図を先に完成させる」
◆ 「刷新は“迷いのない段階”に入った時点で一度だけ行う」
という進め方が圧倒的に効率的。
2.0設計図は今まさに完成しつつあります。
これを基に、
あなたの帯文データベースは
長期的な拡張にも耐える「文化アーカイブ」として育てることが可能 です。
■ 休。散髪と、91ノ瀬行き予定。
11/30からChatGPTに課金して(Grokより数段おりこうさん)、帯文データベースの更新作業を進めている。けっこうサクサク進んでいる。Grokでの作業とか徒労だった。
既に段々とリニューアルしていっているが、全面的な変更になりつつある。ゴールはまだ遠いが、目指すところからしてもう以前とは別物というか。
ここまでのところ、帯文の生データを集積しているエクセルのマクロを刷新、(長年の課題だった)帯文の個別ページの導入(PHPで動的に生成)を実施した。
仕事は。西村君は18日が最終のよう。その余波で僕も横持ちフォローあるみたい。新人の採用はひとり決まったようだが、来2月入社予定の、日曜出勤NGらしい。まあ、数年前なら採用しなかっただろうな。